Why You Never Knew How Much You Needed Ecological Metadata Language
Metadata, or data about data, is a bit like the air we breathe: Absolutely essential but not something we see directly or think about much. Without metadata, many things people use every day – such as Google, which relies on metadata to search and sort webpages – wouldn't be possible.
NCEAS has long been part of the effort to make metadata work better for science, which in turn helps science work better for society. With the release of a new version of metadata standards we helped develop, called Ecological Metadata Language (EML), we’ve made another big step in improving researchers’ ability to use and reuse data to create knowledge.
Metadata is a critical part of open science. What scientist hasn't received a data file from a colleague only to ask them five minutes later what each column means, or found a dataset online with cryptic variable names? Documenting datasets with metadata, such who conducted the data collection and with which sampling methodologies, ahead of time is critical so other scientists, and a scientist’s future self, can understand and use their datasets.
Fundamental to that future use, however, is a standardized vocabulary for metadata, and that is why Ecological Metadata Language matters. EML is a structured metadata language, which lays out a vocabulary of common concepts for dataset variables, such as its title, creator, or what that mysterious column "temp" in an Excel spreadsheet is all about. (And despite its name, this language can be applied to any kind of data.)
For example, if you had a dataset on soil temperature, with EML you could assign pre-defined terms and units to an otherwise undocumented column, such as “instantaneous temperature” or “Celsius.” With a structured metadata language like this, many metadata records can be combined into a single database, which allows for the creation of search interfaces for finding data. The result is like a Google for data, allowing users to query their specific interests, such as “datasets with soil temperatures north of 50° latitude.”
Using a common metadata language greatly increases the chances scientists will be able to understand, find, and use each other’s data in the future, because each field is well defined. It also prevents the otherwise inevitable breakdown in communication that comes when scientists collaborate beyond their lab groups and attempt to translate their homegrown documentation standards.
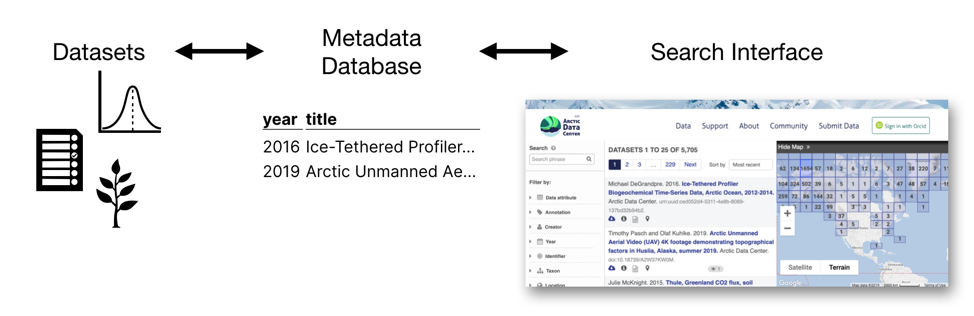
EML is a secret weapon behind the data repositories created by NCEAS, such as the KNB Data Repository and the Arctic Data Center, which automatically generate metadata when scientists submit datasets.
Like all languages, EML evolves with the needs and times of its users, and with the release of EML 2.2.0, it just got easier for ecologists to communicate about their data. Here are some reasons to be excited about this update:
- Improved formatting support: For the longest time, it was tricky to produce common types of formatting for abstracts, methods, or other text fields in EML. The update adds support for Markdown, which an increasing number of scientists are using. Markdown support also means you can now include mathematics, inline images, tables, and many other useful formatting techniques that were difficult or impossible before.
- Say what you mean better: Being clear about what you mean is important. When picking names for columns in spreadsheets, you may know what you mean, but others may not. While EML did previously support describing column names in detail – with a name, definition, and units, for example – now, with EML 2.2.0, you can annotate your columns (and more) with terms from controlled vocabularies to be even clearer about what you mean.
- Copy, Paste, Cite: Entering literature references in the previous version of EML was possible, but somewhat complicated. With EML 2.2.0, you can now enter a citation by just copying and pasting the BibTeX from your citation manager or journal website of choice.
- License it: Datasets and metadata are (slowly) becoming first-class research artifacts and, with that, licensing has moved to the forefront of data archival and publication. EML 2.2.0 adds support for asserting the licensing of your metadata or other parts of your research, such as software.
If you're curious for more details on the above and what else is new, head over to the EML website and have a look.
Bryce Mecum has been a science software engineer with NCEAS since 2015.